
Whether it is good or not Azure HDInsight needs unique name across Azure to create new instance. This leads to the requirement of name availability check feature. There are multiple mechanisms like calling API or checking the URL https://<proposed hdi name>.azurehdinsight.net for existence.
Lets see how the Azure portal handles this check?
Azure Portal using CheckNameAvailability API for HDInsight cluster
The best friend is F12 browser tools to check how a web app like Azure Portal works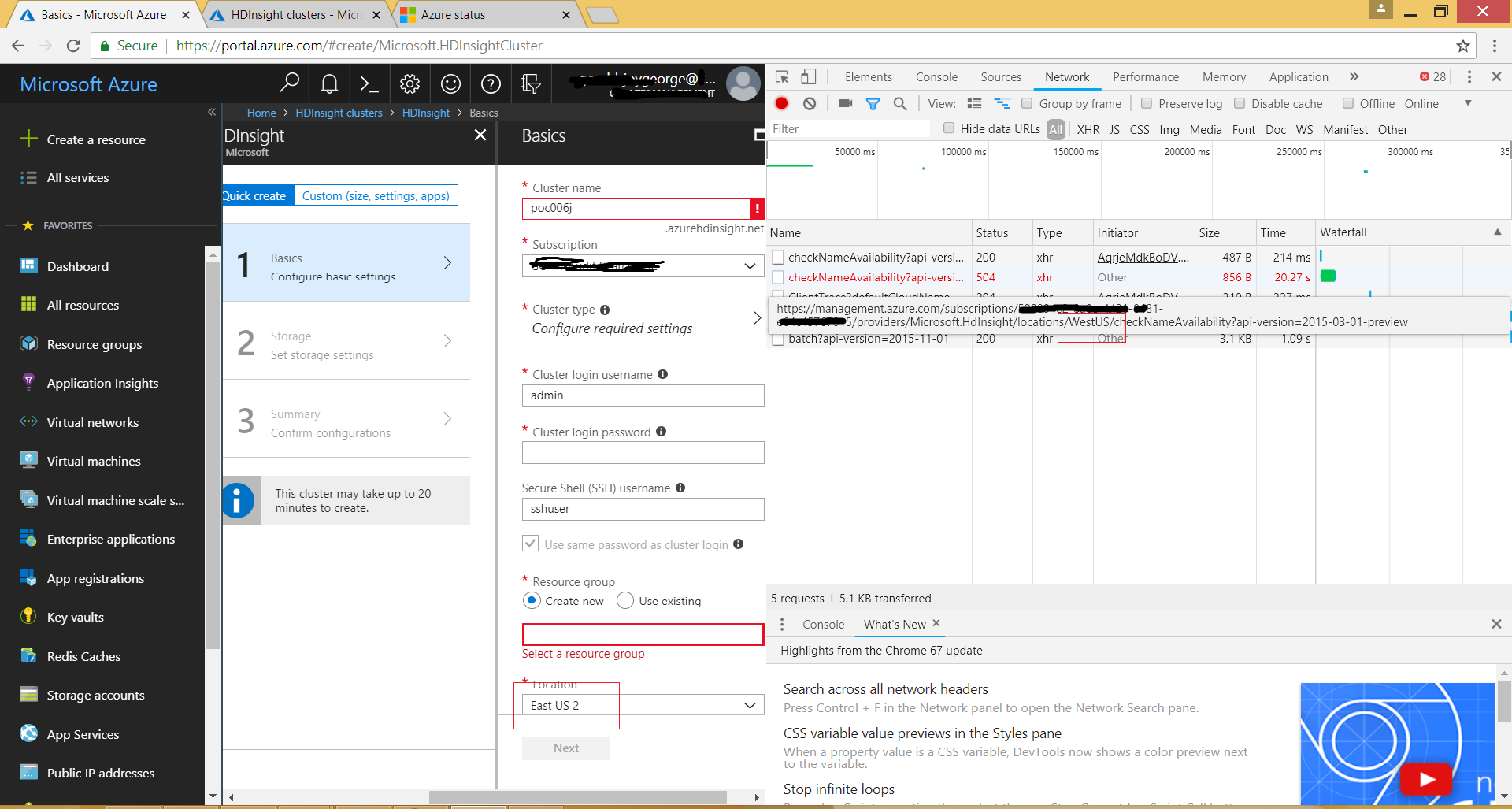
https://docs.microsoft.com/en-us/rest/api/cdn/checknameavailabilitywithsubscription/checknameavailabilitywithsubscription
But the above article talks only about checking the name using Microsoft.Cdn provider. HDInsight with check name availability seems undocumented. Below is the URL format for doing so which portal uses.
POST https://management.azure.com/subscriptions/{subscriptionId}/providers/Microsoft.HDInsight/checkNameAvailability
Why the API end point is to West US while the resource to be created in East US?
This is the magic of portal. It seems portal is hosted in West US and thus it uses the API end points there. When the screenshot was taken the portal was opened from New Jersey,USA without any VPN and ISP seems from East US itself. So no chance for Azure to redirect client to West US by recognizing the location.
Why there is Http 504 in the screenshot?
This story seems related with an outage happened last Wednesday (13Jun2018) in South Central US Azure region. During that time, if we tried to create HDInsight it will show the name is not available.
Under the hood it tries to reach to the West US end point for checking for the name availability and it error out with gateway timeout. It might be because internally it is not able to contact SouthCentral region. When the timeout happens, Portal thinks the name is not available and displays the message. What a thinking?
Ideally it should have been understood the http 504 and acted accordingly. As per Azure or any cloud design philosophy, failures are expected. Why not accept that failure occurred in the portal itself?
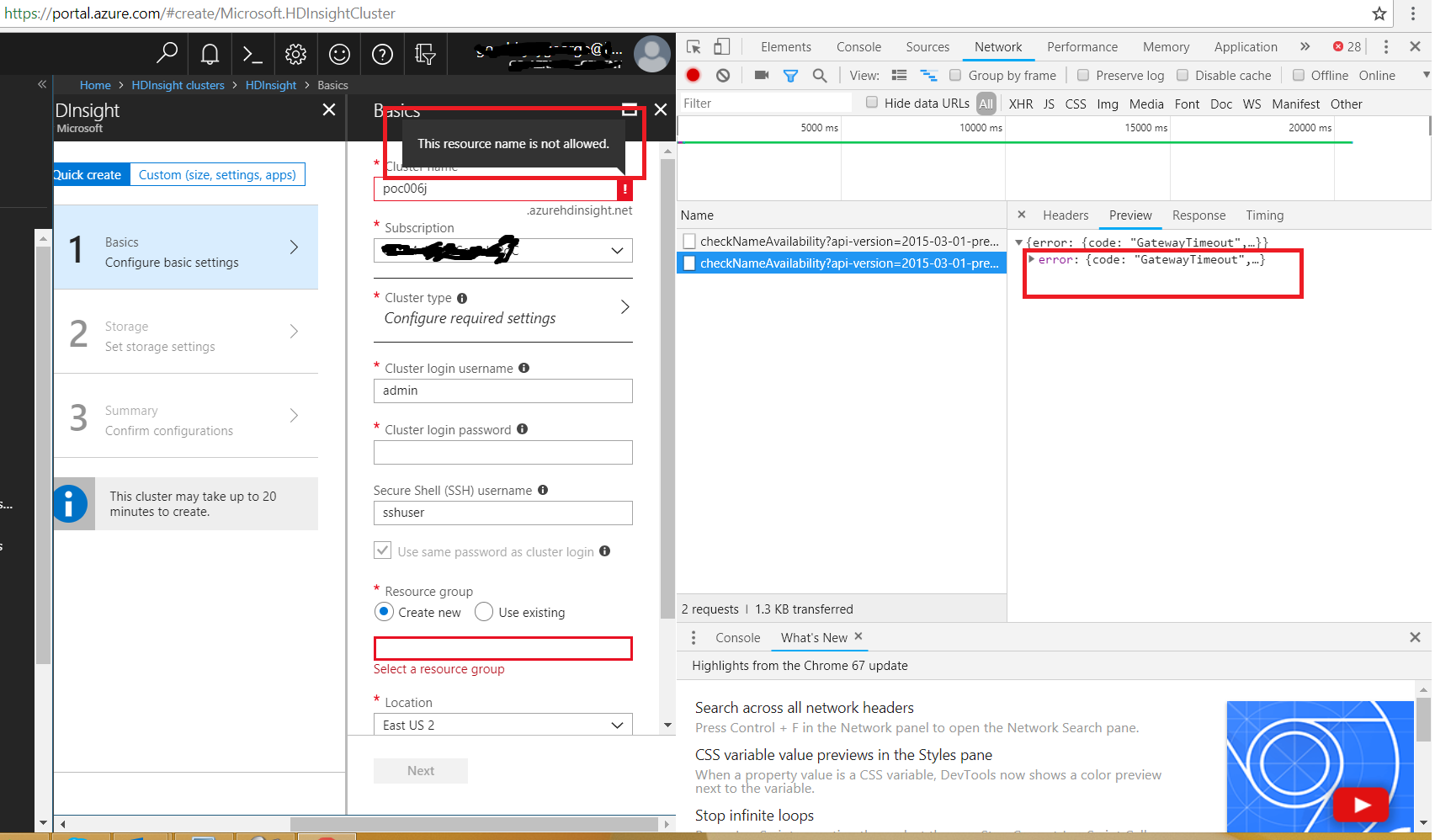
As it is mentioned the issue seems related with outage in South Central US, there is no proof ensuring causation only the time range is same. Screenshot of outage details below.
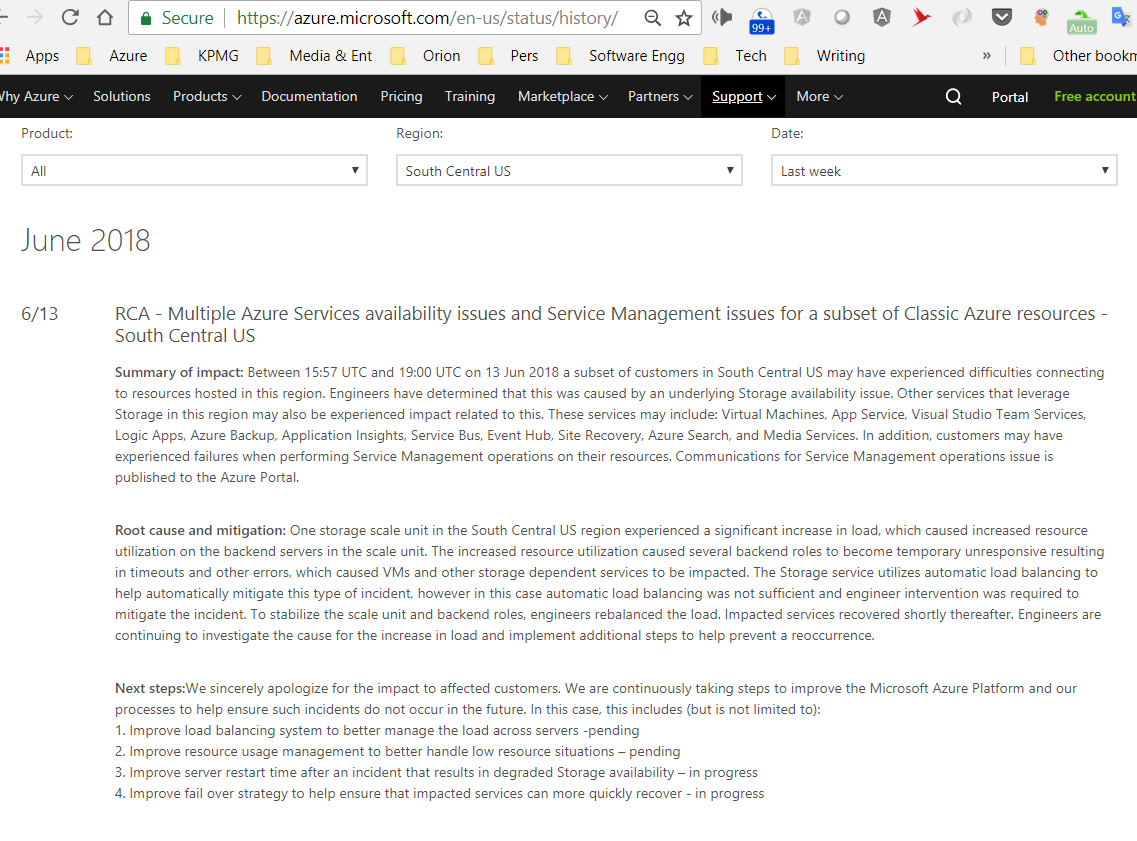
It was fun to debug this by sitting near to a Microsoft ADM. The same has been communicated to Microsoft via him. Hopefully they will fix it soon.
Happy debugging...

No comments:
Post a Comment